はじめに
音声処理の練習もかねて、低機能なスマートスピーカーのようなもの(以後、スマートスピーカーもどき)を作っている。 経緯はスマートスピーカーもどきを作る – 目次を参照。
この記事では、スマートスピーカーもどきに話しかけるときに使うワード(「OK, Google」などに相当)の発声を検出する。 方法としては、TensorFlowを用いて音声の分類を行う機械学習モデルを作成する。
環境
- Windows 10
- AMD Ryzen 9 3900X
- NVIDIA GeForce RTX 2080 SUPER
- CUDA 11.2
- cuDNN 8.1.1
- Python 3.10.5
- TensorFlow 2.10.1
- librosa 0.9.2
- PyAudio 0.2.12
音声データの準備
マイク
マイクはサンワサプライのUSB接続の無指向性マイクMM-MCUSB22を使用した。開発用のPCにも、実運用で使用する予定のRaspberry Pi 400にも接続できる。
ちなみにこのマイクを買う前に別のメーカーのWeb会議用スピーカーフォンを買ったのだが、マイク感度が低く今回の目的では使用が難しかった。スマートスピーカー(もどき)にはある程度離れたところから話しかけるため、それなりに高感度なマイクが必要と思う。
録音
スマートスピーカーもどきに話しかける用のワードを決めて、それを何回もマイクに向かって発声する。ときどき声の調子やスピードなどを変えて発声した。
なお、1回の発声ごとに分けて録音するのは手間がかかるので、少しの時間を空けて何度も発声したものを録音した後、後述のコードで個々の発声部分を切り出すことにした。
録音には、Audacity(オープンソースの録音・音声編集ソフトウェア)を使用し、モノラル、サンプリング周波数44.1kHzで録音、16ビットPCMのWAVファイルとして保存した。
録音では1000回以上ワードを連呼したのだが、なかなか大変なので、苦痛に感じないようなワードの設定が重要である。
また、ワードの発声とは別に、適当に独り言をしゃべったり、物音を立てたりしたものを1時間程度録音した。これは、ワードの発声でない音声データとして使用する (以降、「ブランク」と表記する)。
ワードの発声部分の抽出
ワードを連呼した音声データ(WAVファイル)を、以下のようなコードで個々の発声部分に切り出して、個別のWAVファイルに保存した。
Pythonファイルの実行時の引数に、ワードを連呼したWAVファイルを含むディレクトリを指定すると、その中にsampleディレクトリが作成され、さらにその中に切り出されたWAVファイルのセットが保存される。
※実際に使用する場合は、get_sound_ranges()のパラメータを適当に調整する必要がある。
発声部分は、単純に、大きな振幅がそれなりの頻度でみられる部分としている(get_sound_ranges()が発声部分の範囲を返す)。
なお、1秒に44,100点のサンプルがあり、それなりの回数のループになるため、Numbaを用いて高速化をしている(@njitデコレータ)。Numbaについては以下の記事を参照。
そのため、get_sound_ranges()では、一応、結果(ranges)の格納にlistではなく、Numbaで最適化しやすいNumPy配列を使用している (ただし、今回の場合はほとんど意味はないと思う)。
split_sound()で音声データの前後をトリミングしているのは、Audacityの録音・停止ボタンをクリックしたときの音を落とすためである。
import os
import sys
import glob
import wave
import numpy as np
from numba import njit
@njit
def get_sound_ranges(data, sample_rate, threshold, min_duration, min_interval_seconds, max_ranges=10000):
ranges = np.zeros((max_ranges, 2), dtype=np.int64)
n = 0
min_interval = round(min_interval_seconds * sample_rate)
c = min_interval
_silent = True
start = 0
for i, v in enumerate(data):
silent = False
if abs(v) < threshold:
c += 1
if c >= min_interval:
silent = True
else:
c = 0
if _silent is not silent:
if silent:
if i - min_interval//2 - start >= min_duration * sample_rate:
ranges[n, 0] = start
ranges[n, 1] = i - min_interval//2
n += 1
if n >= max_ranges:
break
else:
start = max(i - min_interval//2, 0)
_silent = silent
return ranges[:n]
def split_sound(input_file, output_dir, trim_seconds=0.5):
with wave.open(input_file, "rb") as wf:
# とりあえずモノラル16ビットPCMのみ対応
assert wf.getnchannels() == 1
assert wf.getsampwidth() == 2
data = wf.readframes(wf.getnframes())
data = np.frombuffer(data, dtype=np.int16)
sample_rate = wf.getframerate()
# 前後をトリミング
trim = round(trim_seconds * sample_rate)
data = data[trim:-trim]
ranges = get_sound_ranges(data, sample_rate, threshold=1200, min_duration=0.5, min_interval_seconds=0.2)
prefix = os.path.splitext(os.path.basename(input_file))[0]
for i, (start, end) in enumerate(ranges):
filename = os.path.join(output_dir, f"{prefix}_{i+1}.wav")
with wave.open(filename, "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(sample_rate)
wf.writeframes(data[start:end])
if __name__ == "__main__":
target_dir = sys.argv[1]
output_dir = os.path.join(target_dir, "sample")
if not os.path.isdir(output_dir):
os.mkdir(output_dir)
for filename in glob.glob(os.path.join(target_dir, "*.wav")):
split_sound(filename, output_dir)
パラメータを調整すると大体うまく切り出せたが、雑音部分が保存されたり、複数回の発声が1個のファイルに保存されたりする場合があり、生成されたファイルをすべて聞いて問題ないか確認する必要があった。
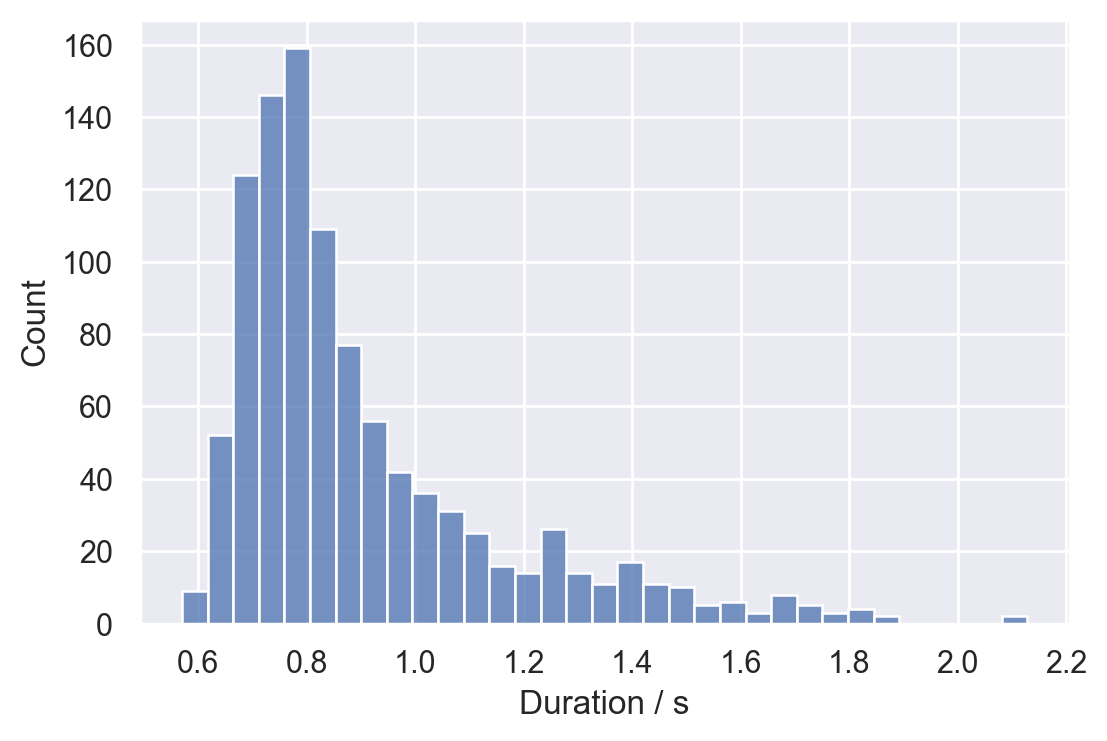
合計で1023個のサンプル(WAVファイル)が準備できた。長さの分布を調べたところ、以下のようになった。ほとんどが2秒以内で、中央値は0.82秒だった。
音声データの画像化
メルスペクトログラムについて
音声処理では、音声データをスペクトログラムに変換して画像として取り扱うことも多いようだ。 スペクトログラムは、短時間フーリエ変換(STFT)などによって生成され、一方の軸が周波数、もう一方の軸が時刻に対応する(2次元の)画像とみなすことができる。画像上の各点の値が、音声データの当該時刻における当該周波数の強度に相当する。
ここでさらに、人間の聴覚特性(低周波の方が聞き分けやすい)を参考にして情報を削減したものが、メルスペクトログラムと呼ばれるもので、機械学習の前処理によく使われるようだ。
例えば、「こんにちは」という合成音声の波形(上図)とメルスペクトログラム(下図)は以下のようになる。 メルスペクトログラムの縦軸(周波数)の目盛りは、線形でないことに注意する (上述の理由で低周波の領域が広くなっている)。
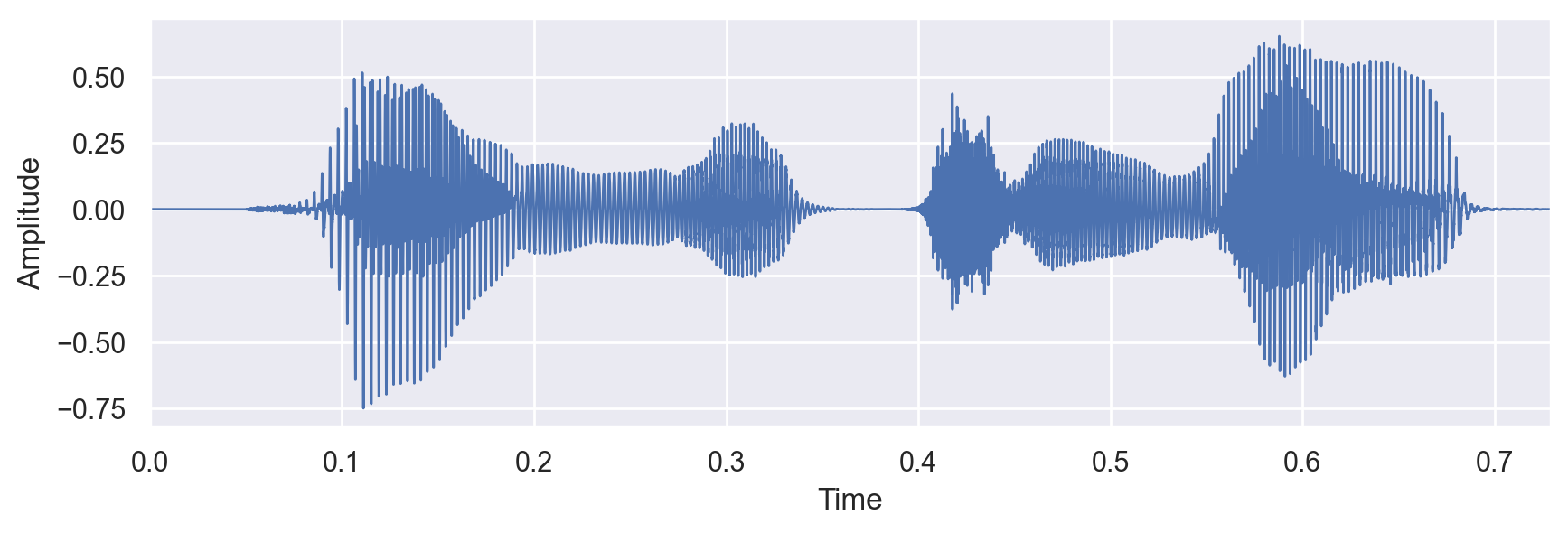
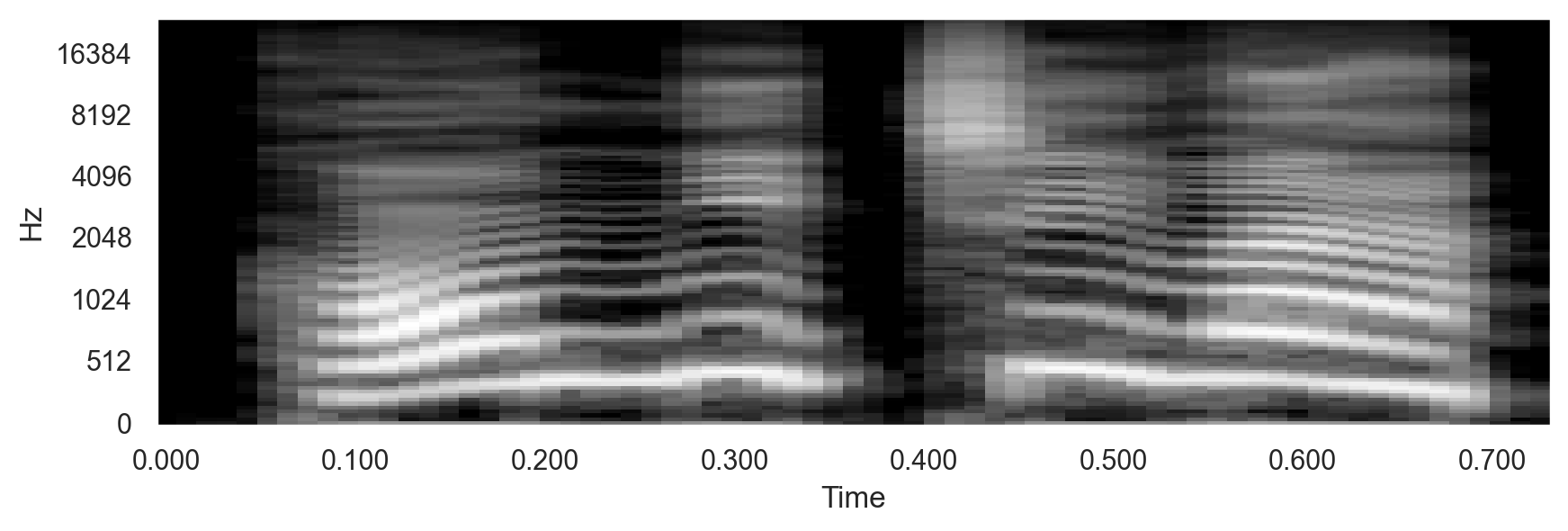
注:合成音声はOpen JTalkを用いて(実際にはラッパーのpyopenjtalkを用いて)作成した。また、後述のlibrosaを用いてメルスペクトログラムを作成した。
Pythonでメルスペクトログラムを生成するには、librosaを使用すると簡単である。
例えば、JupyterLab/Notebookで以下のコードを実行するとkonnichiha.wavの音声データのメルスペクトログラムを表示できる。ここではメルスペクトログラムは対数(㏈)に変換してグレースケールで表示している。
import librosa
import librosa.display
data, rate = librosa.load("konnichiha.wav", sr=None)
s = librosa.feature.melspectrogram(y=data, sr=rate)
s_db = librosa.power_to_db(s)
librosa.display.specshow(s_db, sr=rate, x_axis="time", y_axis="mel", cmap="gray")
なお、スペクトログラムはいわゆる声紋であり、逆変換も可能なため、プライバシー的な観点から、この記事には私の声の音声データそのもののほか、そのスペクトログラムについても掲載しないことにする。
メルスペクトログラムの生成とデータセットの分割
以下のコードでワードのWAVファイル(1023個)からメルスペクトログラムを生成して画像として保存した
(Pythonファイルの引数にWAVファイルを含むディレクトリを指定すると、その中にspecディレクトリが作成され、さらにその中に保存される)。
import os
import sys
import glob
import librosa
import matplotlib.pyplot as plt
target_dir = sys.argv[1]
output_dir = os.path.join(target_dir, "spec")
if not os.path.isdir(output_dir):
os.mkdir(output_dir)
for filename in glob.glob(os.path.join(target_dir, "*.wav")):
data, rate = librosa.load(filename, sr=None)
s = librosa.feature.melspectrogram(y=data, sr=rate, n_fft=1024, n_mels=128)
image_file = os.path.splitext(os.path.basename(filename))[0] + ".png"
plt.imsave(os.path.join(output_dir, image_file), librosa.power_to_db(s), origin="lower", cmap="gray")
一方、ブランクのWAVファイル(合計1時間程度の2個のファイル)は、15秒ごとに区切って変換・保存した (Pythonファイルの引数にWAVファイルを指定すると、同じ階層にそのファイル名(拡張子を除く)と同名のディレクトリが作成され、その中に保存される)。合計で275枚の画像が生成された。
15秒ごとに区切ったのは、後述の学習/検証/テストセットの分割の都合上であまり深い意味はない。
import os
import sys
import librosa
import matplotlib.pyplot as plt
filename = sys.argv[1]
output_dir = os.path.splitext(filename)[0]
prefix = os.path.splitext(os.path.basename(filename))[0]
if not os.path.isdir(output_dir):
os.mkdir(output_dir)
data, rate = librosa.load(filename, sr=None)
step = 15 * rate
for i, pos in enumerate(range(0, len(data), step)):
s = librosa.feature.melspectrogram(y=data[pos:pos+step], sr=rate, n_fft=1024, n_mels=128)
plt.imsave(os.path.join(output_dir, f"{prefix}_{i}.png"), librosa.power_to_db(s), origin="lower", cmap="gray")
次に、作成した画像のセットを学習/検証/テストセットに分割する (split.py)。ワードの画像が_data/word/specに、ブランクの画像が_data/blank/specにそれぞれまとまっているとして、以下のようなコマンドで分割した。
この場合、data/wordの下にtrain(学習用)、valid(検証用)、test(テスト用)ディレクトリが作成され、それぞれに対応するワードの画像が入る。また、data/blankの下のtrain、valid、testには、それぞれに対応するブランクの画像が入る。
> python split.py _data/word/spec data/word
n_train: 656
n_valid: 163
n_test: 204
> python split.py _data/blank/spec data/blank
n_train: 176
n_valid: 44
n_test: 55
split.py
import os
import sys
import glob
import shutil
import numpy as np
def copy(target_files, target_dir):
if not os.path.isdir(target_dir):
os.mkdir(target_dir)
for filename in target_files:
shutil.copy2(filename, target_dir)
src_dir = sys.argv[1]
dest_dir = sys.argv[2]
src_files = glob.glob(os.path.join(src_dir, "*.png"))
np.random.default_rng(5116).shuffle(src_files)
n_test = len(src_files) // 5
n_valid = (len(src_files) - n_test) // 5
n_train = len(src_files) - n_test - n_valid
copy(src_files[:n_train], os.path.join(dest_dir, "train"))
copy(src_files[n_train:n_train+n_valid], os.path.join(dest_dir, "valid"))
copy(src_files[n_train+n_valid:], os.path.join(dest_dir, "test"))
print(f"n_train: {n_train}")
print(f"n_valid: {n_valid}")
print(f"n_test: {n_test}")
モデル入力用画像の生成
今回は、入力にワードの音声に相当するものが含まれているかどうかを判定する(入力を2クラスに分類する)モデルを作成する。ここでその入力画像を準備する。
ワードの音声データはほとんど2秒以内だった。今回、このワードの音声のメルスペクトログラムと、ブランクの音声データ(ワードを含まない声や雑音などのデータ、無音とは限らない)のメルスペクトログラムを切り貼りして、約3秒間に相当するメルスペクトログラムの画像を生成する。以下の概略図のように3個のメルスペクトログラム画像を横(時刻方向)に並べて、幅256px、高さ128pxのモデル入力画像を作成する。

-
(ワードを含むクラス) 合計約3秒間の中で、ワード音声部分が開始する時刻はランダムであり、それ以外の2個のブランク音声部分はそれぞれ、15秒ごとに分割されたスペクトログラムのランダムな部分から切り出されたものを使用する。また、これら3個のスペクトログラムは特定の割合以下のランダムな割合で横方向(時刻方向)に拡大・縮小されたものが使用される。
-
(ワードを含まないクラス) ワードのスペクトログラムの代わりに、3個目のランダムに切り出されたブランクのスペクトログラムを使用する。それ以外はワードを含むクラスと同じ。
画像の生成はジェネレータを用いて必要な時に行うことにする。以下にそのコードを掲載する (画像の操作にはOpenCVを用いた)。
sample()がサンプルを生成するイテレータを返すジェネレータである。サンプルはワードを含むクラスと含まないクラスが半々の割合で生成される。
stepsパラメータに整数を渡すと、その回数だけバッチを生成した後、乱数生成器をリセットするようになる。
これは、学習の際に常に同じ検証セットで評価されるようにするための仕組みである。
word_image_gen.py
import os
import glob
import cv2
import numpy as np
class WordImageGenerator:
def __init__(self, word_image_dir, blank_image_dir, filename_pattern="*.png", total_width=256, height=128, resize_ratio=0.2):
self.rng = None
self.total_width = total_width
self.height = height
self.resize_ratio = resize_ratio
self.word_images = self.load_images(word_image_dir, filename_pattern)
self.blank_images = self.load_images(blank_image_dir, filename_pattern)
self.word_image_widths = [img.shape[1] for img in self.word_images]
def load_images(self, image_dir, filename_pattern):
images = []
for filename in glob.glob(os.path.join(image_dir, filename_pattern)):
img = cv2.imread(filename)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
assert img.shape[0] == self.height
images.append(img)
return images
def get_word_image(self, scale):
img = self.word_images[self.rng.integers(len(self.word_images))]
width = round(img.shape[1] * scale)
return cv2.resize(img, dsize=(width, img.shape[0]))
def get_blank_image(self, scale, width=None):
if width is None:
_w = self.word_image_widths[self.rng.integers(len(self.word_image_widths))]
width = round(_w * scale)
else:
_w = round(width / scale)
img = self.blank_images[self.rng.integers(len(self.blank_images))]
pos = self.rng.integers(img.shape[1] - _w + 1)
img = img[:, pos:pos+_w]
return cv2.resize(img, dsize=(width, img.shape[0]))
def get_composite_image(self, word=True):
scale_a, scale_m, scale_b = 1 - self.resize_ratio + self.rng.random(3) * self.resize_ratio * 2
if word:
img_m = self.get_word_image(scale_m)
else:
img_m = self.get_blank_image(scale_m)
width_m = img_m.shape[1]
width_a = self.rng.integers(self.total_width - width_m - 1) + 1
width_b = self.total_width - width_a - width_m
img_a = self.get_blank_image(scale_a, width_a)
img_b = self.get_blank_image(scale_b, width_b)
img = np.concatenate((img_a, img_m, img_b), axis=1, dtype=np.float32) / 255
return img
def sample(self, steps=None, batch_size=32, seed=5116):
while True:
self.rng = np.random.default_rng(seed)
step = 0
while steps is None or step < steps:
inputs = np.zeros((batch_size, self.height, self.total_width), dtype=np.float32)
targets = self.rng.integers(2, size=batch_size)
for i in range(batch_size):
inputs[i] = self.get_composite_image(targets[i] == 1)
yield inputs, targets
step += 1
余談であるが、現在のNumPyでは、乱数を用いる新しいコードを書くときはnumpy.random.randint()などを使用せず、numpy.random.Generatorのインスタンスをnumpy.random.default_rng()などで生成し、それが持つintegers()などのメソッドを使用することが推奨されている。
モデルの構築
ここまでで音声データを画像として扱えるようになったので、TensorFlowを使用して、特に画像の認識に優れている畳み込みニューラルネットワーク(convolutional neural network; CNN)を用いたモデルを構築する。幅256px、高さ128pxのグレースケール画像を入力とし、畳み込み層と最大値プーリングを3回繰り返した後、全結合層に接続する。
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential()
model.add(layers.Conv2D(64, (3, 3), activation="relu", input_shape=(128, 256, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(32, activation="relu"))
model.add(layers.Dense(1, activation="sigmoid"))
model.summary()は以下の通り。パラメータ数は約180万個となった。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 126, 254, 64) 640
max_pooling2d (MaxPooling2D (None, 63, 127, 64) 0
)
conv2d_1 (Conv2D) (None, 61, 125, 64) 36928
max_pooling2d_1 (MaxPooling (None, 30, 62, 64) 0
2D)
conv2d_2 (Conv2D) (None, 28, 60, 64) 36928
max_pooling2d_2 (MaxPooling (None, 14, 30, 64) 0
2D)
flatten (Flatten) (None, 26880) 0
dense (Dense) (None, 64) 1720384
dropout (Dropout) (None, 64) 0
dense_1 (Dense) (None, 32) 2080
dense_2 (Dense) (None, 1) 33
=================================================================
Total params: 1,796,993
Trainable params: 1,796,993
Non-trainable params: 0
_________________________________________________________________
学習と評価
先ほど準備したWordImageGeneratorを使用してデータを読み込む。
from word_image_gen import WordImageGenerator
train_gen = WordImageGenerator("data/word/train", "data/blank/train")
valid_gen = WordImageGenerator("data/word/valid", "data/blank/valid")
test_gen = WordImageGenerator("data/word/test", "data/blank/test")
アーリーストップ(val_lossが最低を更新しないエポックが16回連続するとストップ)を設定し、val_lossが最低を更新したときにモデルを保存するようにして、学習させた。
callbacks = [tf.keras.callbacks.EarlyStopping(patience=16),
tf.keras.callbacks.ModelCheckpoint("checkpoint/word_image_model.h5", save_best_only=True)]
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
valid_steps = 32
history = model.fit(train_gen.sample(), steps_per_epoch=64, epochs=256,
validation_data=valid_gen.sample(valid_steps), validation_steps=valid_steps,
callbacks=callbacks)
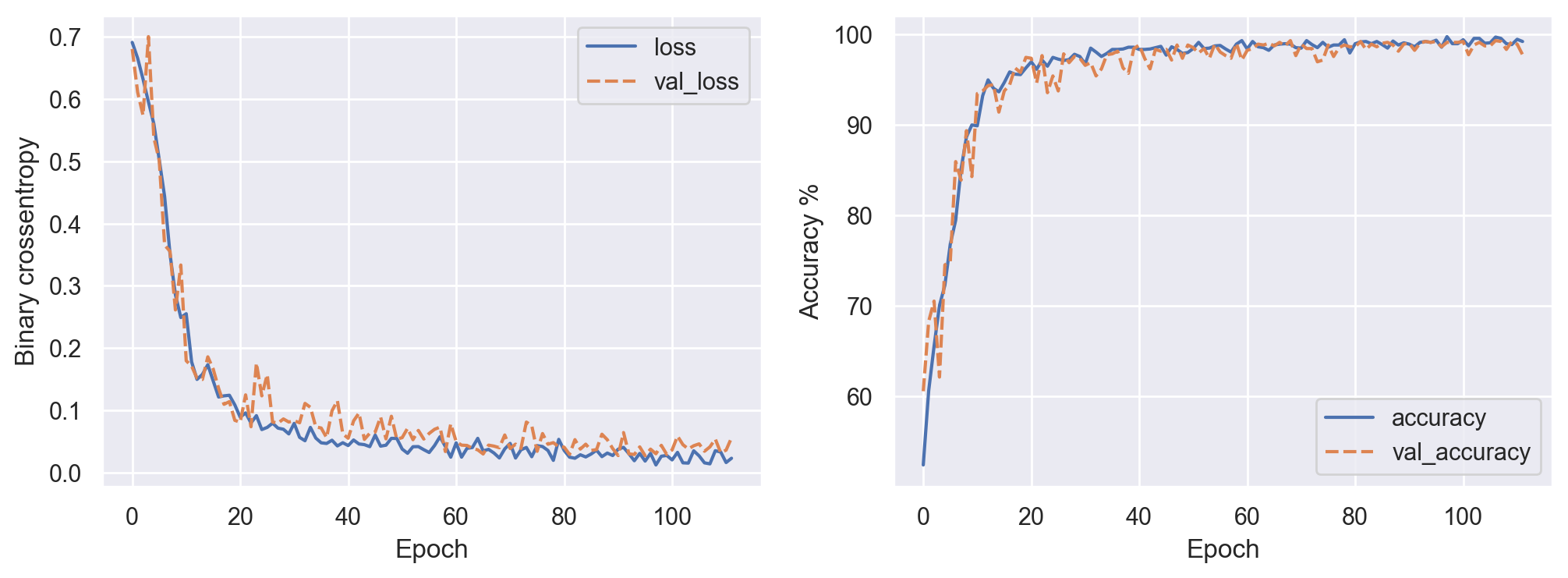
出力は以下の通り。私の環境では数分で終了(112エポックでアーリーストップ)した。
Epoch 1/256
64/64 [==============================] - 6s 34ms/step - loss: 0.6911 - accuracy: 0.5239 - val_loss: 0.6806 - val_accuracy: 0.6055
Epoch 2/256
64/64 [==============================] - 2s 31ms/step - loss: 0.6658 - accuracy: 0.6060 - val_loss: 0.6111 - val_accuracy: 0.6826
Epoch 3/256
64/64 [==============================] - 2s 31ms/step - loss: 0.6321 - accuracy: 0.6553 - val_loss: 0.5739 - val_accuracy: 0.7051
(中略)
Epoch 96/256
64/64 [==============================] - 2s 31ms/step - loss: 0.0181 - accuracy: 0.9937 - val_loss: 0.0268 - val_accuracy: 0.9922
(中略)
Epoch 112/256
64/64 [==============================] - 2s 30ms/step - loss: 0.0227 - accuracy: 0.9922 - val_loss: 0.0556 - val_accuracy: 0.9775
それなりに順調に検証セットでの損失の減少と正解率の上昇が見られている。
保存されたval_lossが最小となったモデルを読み込み、テストセットを用いて性能を評価した。
WordImageGeneratorは無制限にサンプルを生成するので、stepsは適当に大きめの値に設定した。
model = tf.keras.models.load_model("checkpoint/word_image_model.h5")
model.evaluate(test_gen.sample(), steps=1024)
以下の出力が得られた。正解率が99%を超えており、なかなかうまくいった。
1024/1024 [==============================] - 10s 10ms/step - loss: 0.0215 - accuracy: 0.9924
実際のマイク入力で評価
良い感じのモデルが作成できたので、次に実際のマイク入力を使って評価してみる。 マイク入力は、PortAudioのラッパーである、PyAudioを用いると簡単に取り扱える。
簡単に説明すると、PyAudio.open()のstream_callbackパラメータにコールバック関数を指定すると、それが適当なタイミングで別のスレッドで呼び出されるようになる。今回の場合は、マイク入力がリアルタイムに(少しずつ)コールバック関数recorded()に渡される。recorded()は、直近の約3秒(2.965秒)の音声データをバッファに保存するようになっている。ちょうど3秒ではなく、2.965秒なのは、メルスペクトログラム画像の横幅を256pxにするためである。
メインスレッドでは、約1秒ごとに前述のバッファを参照して、ワードの検出を行う。ワードはほとんどが2秒以内なので、過去3秒のデータから1秒ごとに検出を行えば、ほとんど問題ないはずである。
なお、start()のループ内で素直にtime.sleep(1)としていないのは、検出にかかる時間を(ある程度)考慮するためである。
検出detect()では、直近約3秒間の音のメルスペクトログラムを作成してモデル入力を生成し、推論を行っている。
学習に用いたデータと合わせるため、スペクトログラムの各点を0-255の整数値で表現(量子化)した後に255で割って、各点を0-1 (np.float32)の範囲に収めている (意味があるかはわからない)。
誤検出を減らすために、モデルの出力値(コード中のp)についてのワード検出の閾値を0.5でなく0.9とした (説明の順番が前後するが、このモデルではワード検出時にかなり1に近い値が出ることが多かったため、一応このようにした)。
word_detector.py
import os
import sys
import time
import threading
import pyaudio
import librosa
import numpy as np
# TensorFlowのINFOレベルログの抑制
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "1"
import tensorflow as tf
DURATION = 2.965 # モデルの入力に使用する音の長さ(秒)
RATE = 44100 # サンプリングレート(Hz)
SAMPLE_COUNT = int(DURATION * RATE) # モデルの入力に必要なサンプルの数
class WordDetector:
def __init__(self, model_file):
self.lock = threading.Lock()
self.buffer = b"" # 直近の DURATION 秒の音を保存しておくバッファ
self.model = tf.keras.models.load_model(model_file)
def recorded(self, recorded_data, frame_count, time_info, status):
with self.lock:
self.buffer += recorded_data
self.buffer = self.buffer[-(SAMPLE_COUNT * 2):]
return (None, pyaudio.paContinue)
def start(self):
pa = pyaudio.PyAudio()
stream = pa.open(format=pyaudio.paInt16, channels=1, rate=RATE,
input=True, output=False, stream_callback=self.recorded)
stream.start_stream()
prev_time = time.time()
while True:
now = time.time()
if now - prev_time >= 1:
prev_time = now
if not stream.is_active():
break
with self.lock:
data = np.frombuffer(self.buffer, dtype=np.int16)
if len(data) == SAMPLE_COUNT:
self.detect(data / 2**15)
time.sleep(0.02)
stream.stop_stream()
stream.close()
pa.terminate()
def detect(self, data):
s = librosa.feature.melspectrogram(y=data, sr=RATE, n_fft=1024, n_mels=128)
s = librosa.power_to_db(s)
# sの各値を0-1の範囲に収める
a, b = s.min(), s.max()
s = np.round((s - a) * 255 / (b - a + 1e-10)).astype(np.float32) / 255
s = s[::-1, :] # 上下反転
p = self.model.predict(s[np.newaxis], verbose=0)[0][0]
print("\rp = {:.6f} {:10}".format(p, "Detected!" if p >= 0.9 else ""), end="", flush=True)
if __name__ == "__main__":
wd = WordDetector(sys.argv[1])
wd.start()
Pythonファイルの実行時の引数にモデルファイルを指定して起動すると、検出が始まる。
確かに決めておいたワードを口に出すと、モデルの出力値(p)が上昇し、「Detected!」と表示された。
ワードを発声したときの例
> python word_detector.py checkpoint/word_image_model.h5
p = 0.999980 Detected!
少し試してみると、かなり検出感度(正しいワードを発声したときに検出される割合)が良いことがわかった。 検出時にはモデルの出力値が0.99を超えるような1に近い値が出ることが多い。
また、関係ないことを話していてもモデルの出力値は基本的に低いままだった。
関係ないこと(「こんにちは」)を発声したときの例
p = 0.005085
ただし、設定したワードに近い言葉(韻を踏んだようなものなど)を発声すると、割と誤って検出されてしまう。ただ、それも実用的には許容範囲内に思えた。
しかし、さらにしばらく試してみると、困った問題が見つかった。ビニールや紙の袋をガサゴソする(袋に手を入れて動かしたり、袋を握りつぶしたりして音を出す)とほとんど確実に誤検出されてしまう (モデルの出力値がほぼ1になる)。
ガサゴソ音を出したときの例
p = 1.000000 Detected!
改良
検討1: 学習用のデータを増やす
単純に、ブランクの音声データにガサゴソ音がほとんど入っていないことが原因と思われたため、20分程度ガサゴソしたり、椅子をギコギコ(ガサゴソ音ほどではないが、モデル出力値が高くなる)したりした音を録音して、ブランクの音声データとして追加し、これまでと同様にモデルを作成した。
すると確かに、ガサゴソ音では反応しなくなったが、正しいワードを発声したときにも検出されづらくなってしまった (大きめの声ではっきりと発音する必要があった)。正しいワードでなかなか検出されないとストレスがたまってしまう。
一般に、学習用のデータを増やすことはモデルの性能向上に重要だが、これ以上録音してデータを増やすのも疲れたため、それ以外の方法を検討することにした。
検討2: 人間の直観を取り入れる(適当)
ガサゴソ音のメルスペクトログラムを確認してみる。

全体的に(特に上下にわたって)白っぽく(値が大きく)なっており、幅広い周波数の成分が含まれているように見える。 一方、私が適当なことをしゃべっている音声のメルスペクトログラムは、ガサゴソ音の全体的に白くなったものと違って、もっとメリハリがあり、パターンがあるように見える。もっと大雑把に言えば、ガサゴソ音のスペクトログラムよりも黒っぽく見える。
そこで、入力画像(メルスペクトログラム)が、一定以上白っぽいときは、モデルの出力にかかわらず、ワードを検出しなかったことにしてみる。具体的には、入力画像(最小値0、最大値1に変換済み)のすべての点の平均値でフィルタするだけだ。
ひとまず、3種類の音声データのメルスペクトログラムの画像(最小値0、最大値1のモノクロ画像で、時間の長さ以外はword_detector.pyと同様にして作成)について、それぞれすべての点の平均値を算出した。
具体的には、私の声のメルスペクトログラムの平均値は0.25、ガサゴソ音の平均値は0.59、冷蔵庫のブーンという音(別の雑音の例)の平均値は0.38だった (それぞれ10秒~30秒程度の音声データを使用)。
短い音声を使用した大雑把な検討であり、数値はあまり信頼できないが、これらの結果からフィルタリングの閾値は適当に0.4に設定した。
念のため記載するが、メルスペクトログラムの画像はそれぞれについて、最小値が0、最大値が1になるようにスケーリングしているため、例えば、冷蔵庫がブーンとなっているときにしゃべった場合に平均値がそれぞれ単独のときの和(例えば、0.38+0.25)になるわけではないということに注意する。
つまり、ここでの平均値は、元の音の大きさ自体を表しているのでなく、幅広い周波数がまんべんなく、継続的に出ているかどうかを表す指標になっていると考えられる。
このフィルタを導入するには、前述のコード(word_detector.py)のdetect()内の以下の部分
print("\rp = {:.6f} {:10}".format(p, "Detected!" if p >= 0.9 else ""), end="", flush=True)
を以下に変更すればよい。
m = s.mean()
print("\rp = {:.6f}, m = {:.4f} {:10}".format(p, m, "Detected!" if p >= 0.9 and m < 0.4 else ""), end="", flush=True)
実行すると、モデル出力値(p)に加えて、入力画像の平均値(m)も出力され、pが0.9以上で、mが0.4未満のときのみ、「Detected!」と表示される。
ガサゴソ音を出したときの例
> python word_detector_EDITED.py checkpoint/word_image_model.h5
p = 1.000000, m = 0.6104
ワードを発声したときの例
p = 0.999152, m = 0.3172 Detected!
かなり適当な対応であったが、結果としてはとてもうまくいった。
ガサゴソ音を立てると、pに加えてmも上昇し、ワードの発声として検出されることが防止されるようになった。
0.4の閾値も適当に決めたが、ちょうどよかったようだ。
これで、実用上問題はなさそうだ。
まとめ
今回で、スマートスピーカーもどきに話しかけるときのワードの発声の検出が可能になった。